
leetcode 862. 和至少为 K 的最短子数组
题目描述leetcode862. 和至少为 K 的最短子数组
给你一个整数数组 nums 和一个整数 k ,找出 nums 中和至少为 k 的 最短非空子数组 ,并返回该子数组的长度。如果不存在这样的 子数组 ,返回 -1 。
子数组 是数组中 连续 的一部分。
示例 1:
输入:nums = [1], k = 1
输出:1
示例 2:
输入:nums = [1,2], k = 4
输出:-1
示例 3:
输入:nums = [2,-1,2], k = 3
输出:3
提示:
1 <= nums.length <= 105
-105 <= nums[i] <= 105
1 <= k <= 109
题解——单调队列详解今天正好趁着这道题学习了一下单调队列,把过程中我的一些理解记录下来,如有不对的地方,希望大佬们指出。
单调队列与单调栈的区别与联系相比于单调队列,单调栈要常见得多。需要指出的是,这两者并不像栈与队列那样有着截然相反的操作(事实上,单调队列用的并不是 ...

数据结构与算法Week7——贪心算法
贪心算法这周的作业题是三道贪心题。说实话,事先没见过,要独立想出来还是很难的。毕竟贪心就是这样,就好像你明知道前面有一扇门,却在上面摸索半天,也找不到门把手在哪里。贪心也很想脑筋急转弯,假如没有灵机一动,想不到那个方法,就得一直坐牢下去。所以很多算法竞赛也喜欢考贪心,来考察变通能力。
很难说要怎样训练贪心题,或许寻求的就是一种感觉吧(就像语文一样)。找规律也很重要,再有就是数学推理能力。
拿这次的三道作业题举个例子,都是很经典的贪心题。
题目一——活动选择原题链接——435. 无重叠区间 - 力扣(LeetCode)
这道题,如果采用暴力求解,最坏时间复杂度甚至可以达到O(2^n),在n很大时,是很吓人的。而贪心算法可以将复杂度降到O(nlogn)+O(n),其中O(nlogn)是排序的时间复杂度。
我们的贪心策略是:在每次添加活动时,总是保证结束时间尽量早,这可以保证后续能尽可能多地添加活动。而何时开始,对后续添加是无影响的,只影响自己能不能向里面添加。依据这种策略,我们将每个活动按照结束时间排序,并依次检验开始时间是否大于目前的结束时间,如果满足,就添加进去(这个就是满足条件的结 ...
leetcode 901. 股票价格跨度
题目描述leetcode901. 股票价格跨度
编写一个 StockSpanner 类,它收集某些股票的每日报价,并返回该股票当日价格的跨度。
今天股票价格的跨度被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。
例如,如果未来7天股票的价格是 [100, 80, 60, 70, 60, 75, 85],那么股票跨度将是 [1, 1, 1, 2, 1, 4, 6]。
示例:
输入:["StockSpanner","next","next","next","next","next","next","next"], [[],[100],[80],[60],[70],[60],[75],[85]]
输出:[null,1,1,1,2,1,4,6]
解释:
首先,初始化 S = StockSpanner(),然后:
S.next(100) 被调用并返回 1,
S.next(80) 被调用并返回 1,
S.next(60) 被调用并返回 1,
S.next(70) 被调用并返回 2,
S.next(60) 被调用并返回 1,
S.next(75 ...

数据结构与算法Week6——广义表的深度
广义表的深度广义表的定义本周的数据结构与算法继续学习数组和广义表。主要讲了广义表。广义表是一种比较抽象的数据结构,它包含两个部分:原子和表。相较于链表和容器而言,它的元素不止一种,而且由于表可以嵌套,一张广义表是递归定义的。广义表主要应用于LISP语言(实际上LISP语言也只有广义表)。
广义表的表示通常,表用大写字母表示,而原子用小写字母表示,并用括号来体现层次。几个例子如下图:
注意,广义表的递归可以没有出口,比如图中E表。
广义表的深度将广义表的深度定义为所有元素深度的最大值,直观体现就是括号嵌套的最大层数,对于上面的例子,深度如下:A 1, B 1, C 2, D 3, E inf,而这周的编程题便是求广义表的深度。题目如下:
首先考虑每个表中包含的表都在之前输入,那么,我们只需要遍历输入,同时维护一个depth,遇到左括号+1,遇到右括号-1,遇到其他表先加后减,同时在每一步取MAX,最终结果就是这张表的深度,存下来为后面做准备。
然而,未必恰好是这样输入的。很有可能内部的表要在后面输入,比如下面的情况。
123A=(B,C)C=(a)B=(a,B)
应该输出
123in ...

leetcode 779. 第K个语法符号
题目描述leetcode 779. 第K个语法符号
我们构建了一个包含 n 行( 索引从 1 开始 )的表。首先在第一行我们写上一个 0。接下来的每一行,将前一行中的0替换为01,1替换为10。
例如,对于 n = 3 ,第 1 行是 0 ,第 2 行是 01 ,第3行是 0110 。
给定行数 n 和序数 k,返回第 n 行中第 k 个字符。( k 从索引 1 开始)
示例 1:
输入: n = 1, k = 1
输出: 0
解释: 第一行:0
示例 2:
输入: n = 2, k = 1
输出: 0
解释:
第一行: 0
第二行: 01
示例 3:
输入: n = 2, k = 2
输出: 1
解释:
第一行: 0
第二行: 01
提示:
1 <= n <= 30
1 <= k <= 2n - 1
题解——脑筋急转弯:作图理解,c++一行思路先做出前几行的图看一看,可以生成如下一棵满二叉树
可以 ...

leetcode 902. 最大为 N 的数字组合
题目描述leetcode902. 最大为 N 的数字组合
给定一个按 非递减顺序 排列的数字数组 digits 。你可以用任意次数 digits[i] 来写的数字。例如,如果 digits = ['1','3','5'],我们可以写数字,如 '13', '551', 和 '1351315'。
返回 可以生成的小于或等于给定整数 n 的正整数的个数 。
示例 1:
输入:digits = ["1","3","5","7"], n = 100
输出:20
解释:
可写出的 20 个数字是:
1, 3, 5, 7, 11, 13, 15, 17, 31, 33, 35, 37, 51, 53, 55, 57, 71, 73, 75, 77.
示例 2:
输入:digits = ["1","4","9"], n = 1000000000
输出:29523
解释:
我们可以写 3 个一位数字,9 个两位数字,27 个三位数字,
81 个四位数字,243 个五位 ...
数据结构与算法Week5——差分数组
差分数组以本周的练习题引入本周数据结构继续学习数组,主要讲了什么数组的压缩存储,也就是对特殊矩阵(对称矩阵)以及稀疏矩阵怎样减少区间消耗的问题。不过不太好用OJ考察,所以做的题目仍然是对数组的简单处理,第三题有点意思,可以做一些延伸。题目如图。
容易想到,讲师的数目的限制来自于课程重叠。也就是说,如果我们求出课程的最大重叠,也就是讲师的最小数目。观察数据范围,由于时间被限制在0~24了,我们可以对每个时刻,统计正在上的课,最大值就是答案。
需要注意的是,题目认为老师可以立即去上下一节课,也就是说:0~1,1~2这样的情况,只需要1名老师即可。所以,我们可以认为,上课的时间是[begin,end),一个左闭右开区间,所以,我们维护一个长为24的数组(0~23),对每一节课,把[begin,end)中的时间++,然后返回最大值即可。最坏时间复杂度O(24*N)。代码如下:
12345678910111213141516#include <bits/stdc++.h>using namespace std;int main(){ vector<int> ...

分段打表
分段打表技巧什么是打表打表,也叫硬编码,也就是说对问题进行预计算,把结果作为一张常量表写进代码,并在后续求解中使用它,通常是为了降低时间复杂度。
为什么要打表在力扣的评论区,往往有这样的身影,让你点开评论时能卡上半天。定睛一看,竟然是偷出了所有的测试用例,作为一张哈希表,来实现AC。在被一道困难题困扰时,或许这样的行为会让你忍俊不禁,缓解一下情绪。
这样的打表,基本上有三种可能。
第一种是题目超出能力范围,算法根本没学过,求不出答案,那就得利用每次错误返回的用例和答案来打表,错了无数次,就可以偷出所有样例了,打表返回便能通过。
第二种是能求出答案,然而不是最优算法,提交时会超出时间限制,由于本地没有限制,可以在本地先跑完,然后把TLE的样例单独打表。由于极端数据不多,需要打的表也不多。这是最方便的自欺欺人的手段😂。
以上两种都是耍小聪明了,因为一旦添加测试用例,错误和低效就无处遁形了(这也是硬编码的缺陷,就是不可扩充性)。所以在周赛中,即使打表通过,赛后的rejudge也过不了。
然而,还有第三种情况,那就是,由于算法能力有限,能力被限定在一定范围内,如果这个范围很小,那就完全可以预 ...

leetcode 6213. 所有数对的异或和
题目描述leetcode6213. 所有数对的异或和
给你两个下标从 0 开始的数组 nums1 和 nums2 ,两个数组都只包含非负整数。请你求出另外一个数组 nums3 ,包含 nums1 和 nums2 中 所有数对 的异或和(nums1 中每个整数都跟 nums2 中每个整数 恰好 匹配一次)。
请你返回 nums3 中所有整数的 异或和 。
示例 1:
输入:nums1 = [2,1,3], nums2 = [10,2,5,0]
输出:13
解释:
一个可能的 nums3 数组是 [8,0,7,2,11,3,4,1,9,1,6,3] 。
所有这些数字的异或和是 13 ,所以我们返回 13 。
示例 2:
输入:nums1 = [1,2], nums2 = [3,4]
输出:0
解释:
所有数对异或和的结果分别为 nums1[0] ^ nums2[0] ,nums1[0] ^ nums2[1] ,nums1[1 ...
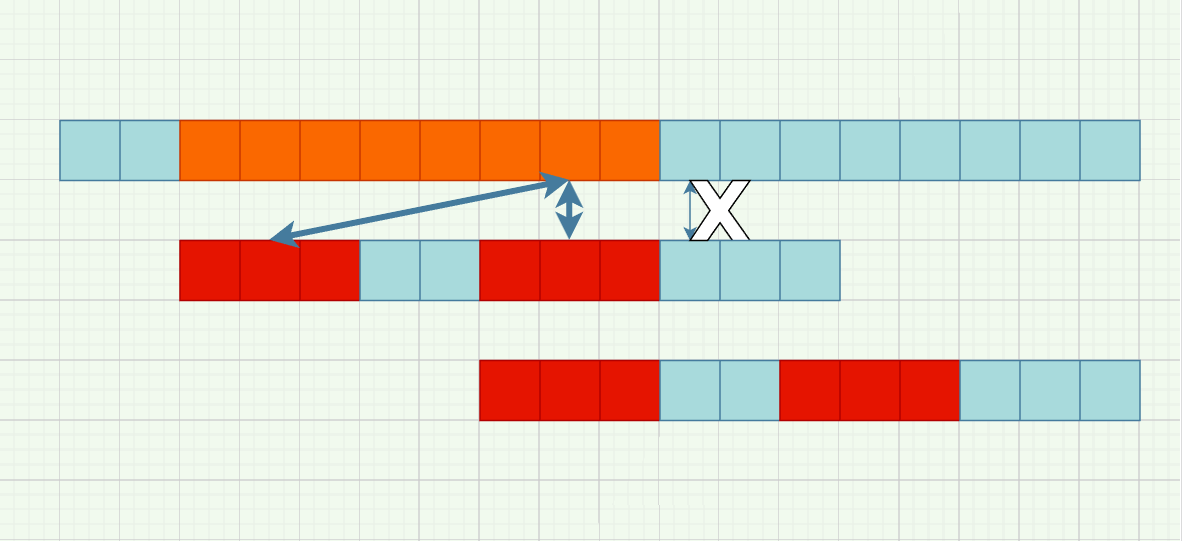
数据结构与算法Week4——KMP算法
字符串模式匹配——KMP算法本周学习了第四章——字符串,其实,基本操作(查找、截取、连接、复制……)早在大一上C语言就已经学过了;而在大一下的C++中,string类也提供了很方便的库函数,所以,我们这节课的重点是KMP算法,这是我们目前课上学的第一个有难度的算法。
KMP算法确实有点“反常识”,导致它抽象而难于理解。我用这篇文章把自己理解的思想记录下来,辅以图解来直观记忆。这些图都是我用draw.io绘制的,转载请注明出处。
什么是KMP算法KMP算法主要是字符串匹配问题的优化。
大部分时候,我们采用的字符串匹配都是O(n*m)的,也就是说,从头到尾遍历主串,以每个字符为开头尝试匹配,如果失配,就回溯到开头的下一个位置继续尝试,直到找到模式串或者遍历完主串。显然,最坏的情况是对主串的每一个位置,都可以部分匹配模式串而只差一个,比如在0000000000000000中找000001,此时,一共要进行n*m次比较。
然而,有这样的一种思路:在我们匹配了一段发现失配时,失配前的那一段是匹配的,也称主串和模式串部分匹配。在上面的例子中,我们匹配了前五个0之后,发现第六个1不匹配,如果按照朴素 ...

